信息引擎项目 | 高效洞察海量信息,助力深度内容解析
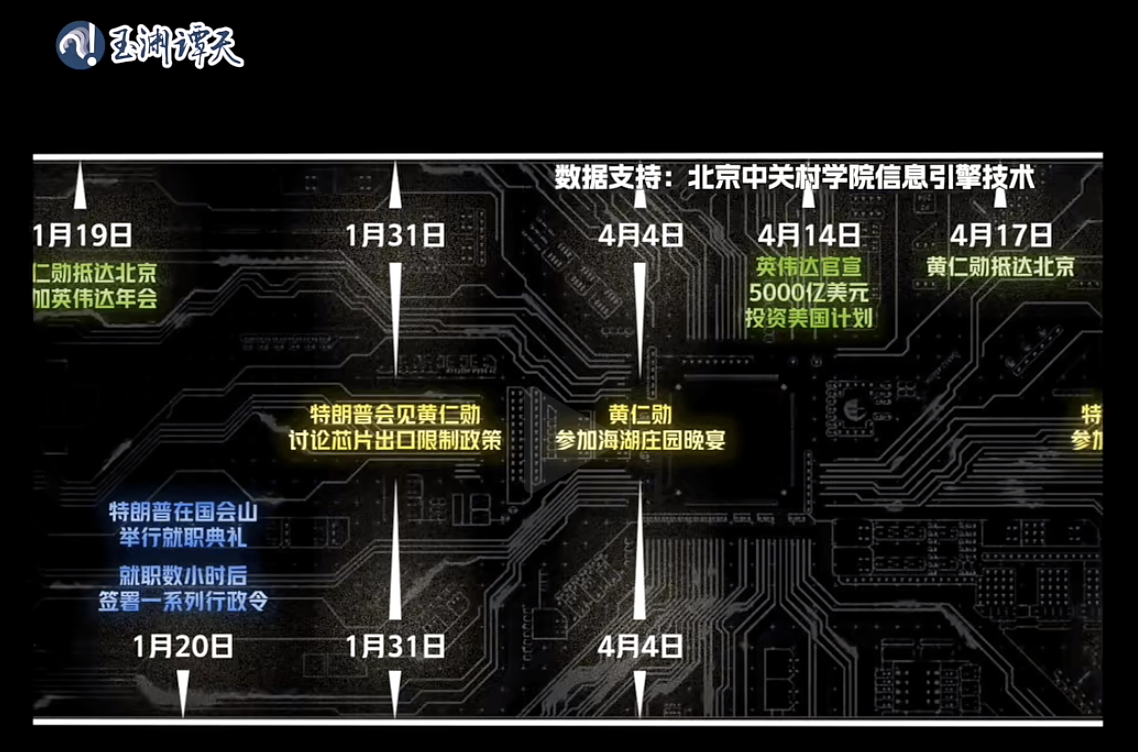
北京中关村学院信息引擎技术助力深度解析复杂国际议题 在全球化与信息技术深度交融的时代,如何从纷繁复杂、浩如烟海的数据中洞察本质、预见趋势,已成为组织和个人在决策时面临的核心挑战。北京中关村学院“信息引擎”项目团队着眼于此,致力于构建从多源信息深度挖掘到复杂系统决策推演的全链路智能技术体系。近日,该项目在“AI + 社会科学”的交叉探索中取得阶段性实践成果,其研发的智能分析系统就“全球芯片产业博弈”等重大国际议题完成深度解析,相关成果在中央广播电视总台新媒体账号“玉渊谭天”的视频报道中获得采用,为前沿人工智能技术系统性地赋能复杂问题研判与重要决策开辟了新的路径。 ...